Notes Devoxxfr 2022 - Vendredi
Après une première journée dense, on continue sur le même rythme, en débutant par 3 keynotes, let's go !
09:00 - 09:20 Futurospective digitale : le futur est-il encore ce qu’il était ?
@Lcinquin, CTO d'Accenture, et ancien PDG d'Octo nous sort sa boule de crystal pour essaye de voir les technos d'avenir, bonne chance !

Notes
- Boule de crystal pour essayer de voir les technos de l'avenir
- L'IA et le cloud sont des sujets
- 3 scénarios
- World tech companies: Puissance des GAFAM, qui font tout pour qu'on le reste chez eux
- Digital Cold War
- Chine: population, start up & régime centralisé
- UE: marché et régulation
- USA: domination culturelle & pure players
- Cyber-guerre mondiale ? Avantage à la Chine
- Digital Detox
- Manque de matière première : de plus en plus compliqué d'avoir du matériel
- Vers le right techs -> respet de l'objet, usage, environnement, humain
- Le GROS sujet : limites de ressources qui vont changer les usages
- Le développeur a une responsabilité: le code écrit aujourd'hui sera l'usage de demain
- Hacker : réutiliser les ressources dispos
Conclusion
Prévisions qui sont certes réalistes, mais pas forcément très rassurantes ! J'aime beaucoup le concept de "right tech", sujet à creuser.
09:25 - 09:45 LesBonsclics, une plateforme pédagogique au service du 1er réseau européen d'aidants numériques.
Thomas VANDRIESSCHE de chez WeTechCare nous présente son travail autour de l'inclusion sociale, via la plateforme "LesBonsClcs".
Notes
- WeTechCare : technologie au service de l'inclusion sociale
- 1/6 personnes n'utilise pas Internet
- 68% de Français déclarent avoir des pb pour l'usage du numérique
- Voir le rapport "Monde social et numérique"
- Les bons clics : plateforme pour l'inclusion numérique, avec des howtos, bonne pratiques
- de la data dispo pour améliorer les usages et etre acteur dans la société
- lien avec les Right Techs
09:50 - 10:10 La quête d'une gouvernance collaborative du web
Le youtubeur Lê Nguyên HOANG explique en quelques exemples le poids de l'IA dans la désinformation, et comment y remédier
Notes
- Sujet sur la désinformation ?
- Le problème: on s'informe par ce que les algos leur suggèrent
- voir tournesol (plateforme de fakenews)
- AI est vulnérable: il ne ressort que ce qu'il a appris, et donc si les "entraineurs" donnent de mauvaises infos, l'AI amplifie ces erreurs.
- Plus de faux comptes, c'est plus de fausses voix pour alimenter les IA.
- Notion de vallée parabolique pour ne pas trop forcer les votes
- Présentation de l'application tournesol.app
10:45 - 11:30 Comment OpenTelemetry peut transformer votre monitoring en unifiant vos logs/metrics/traces - 💻
Suite au premier volet Opentelemetry de jeudi, on continue ce vendredi avec @vbehar qui nous présente la gestion des métriques, logs & traces via le projet OpenTelemetry, comment le mettre en oeuvre, en insistant surtout sur la partie collecteur.
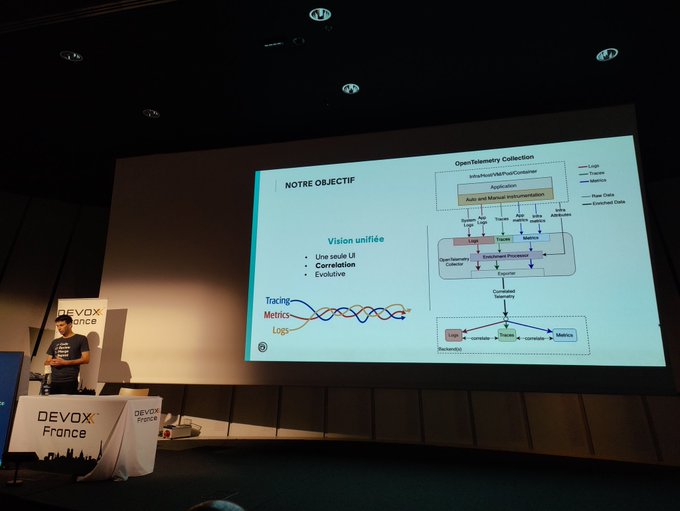
Notes
- Introduction
- Bosse chez Ubisoft pour proposer une infra interne de services managés
- Implémentation Opentelemetry
- Rappel de ce qu'est un log, métriques, traces
- Jaeger pour visualiser ces traces
- Les 3 piliers de l'observabilité c'est bien, mais ça reste 3 silots car les 3 technos ont leur propres "règles"
- Voir cela comme un cube
- Opentelemetry
- Beaucoup de contributeurs
- couche commune pour tous les acteurs de solutions d'observabilité
- specs, implementations, collecteurs
- OpenCensus service, collecteur - killer feature --> à voir
- Collecteur: plateforme de "routage", type logstash
- permet de récupérer logs, métriques, traces, et les renvoyer vers loki, tempo, prometheus, ...
- Grace aux traces, génération de métriques et logs, mais avec de la corrélation
- Comment choisir entre les métriques classiques & celles générées par le tracing ? Ca dépend
Conclusion
Sujet qui complète bien celui de la veille, et montre que les questions d'observabilité et instrumentation dans le codes sont vraiment un point d'attention, continuons ainsi !
J'aime bien le fait d'insister sur le collecteur, car en effet on peut tout à fait combiner traces, métriques, logs. Cependant cela demande un sacré effort d'analyse pour gérer proprement la corrélation.
11:45 - 12:30 À la découverte des Docker Dev Environments
@glours et @rumple font le tour de la fonctionnalité "Dev Environment" de Docker Desktop, pour partager un environnement de dev entre développeurs. CQFD.
Notes
- pb git / dépendance de dev, dur d'avoir un environnnement "propre"
- docker est local first, agnostic, le plus simple possible, utilise compose
- Setup : clone d'un code source dans un volume docker, détection de language pour une utilisation d'une image prédéfinie, et ça ouvre dans vscode
- Possibilité de partager les environnements entre devs
- /!\ Attention images arm/i686
- Injection du conteneur dans la stack compose
Conclusion
Fonctionnalité sympa à connaitre, mais pas sur que dans mon cas cela soit utile ;)
13:00 - 13:15 Profiler un pod dans Kubernetes avec kube-flame
Un quickie sur la génération de flame graphs par @loicmathieu
Notes
- kubectl flame: profiling de conteneurs en prod, qui génère des flame graphs (projet de yahoo)
- s'installe avec krew
- de branden gregg
- automatise le lancement de profilers, et génère les flames graph au format svg
Conclusion
Outil très sympa à connaitre, toujours des flame graphs !! Décidément un des sujets à creuser après ce devoxxfr !
13:30 - 14:15 Les lois universelles de la performance - 💻
Fini les confs autour de l'observabilité, de k8s, je me tente à une conf plus théorique / généraliste, avec celle de @raphaelluta qui nous présente quelques lois mathématiques applicables à l'informatique.

Notes
- On parle de système qui est trop lent
- bcp de maths
- Loi d'amdhal
- faire un calcul, avoir les résultats avant/après parallélisation, on a alors un modèle pour prédire la charge nécessaire
- Anatomie d'une file d'attente (FIFO, etc)
- Possible aussi de modéliser cela: nb d'élément dans la file, temps d'attente, de traitement, ...
- Loi de Little
- Loi d'extensibilité universelle, qui prend en compte les perturbations entre les requêtes
- mesure de latence avec wrk2 (ou gatling, ou autre)
Conclusion
Alors pour le coup, j'ai été très agréablement surpris. Pour moi la meilleure conférence que j'ai vu ! Je ne sais pas si c'est parce que je ne connaissais pas le sujet, mais j'ai été captivé tout le long de la présentation.
En gros, ça ne sert à rien d'aligner les CPUs, RAM, Gbps de BP, tout est question de loi mathématiques (ou presque) ;)
Grand bravo à Raphaël !
14:30 - 15:15 Qu'avons nous appris après un an passé à développer des opérateurs Kubernetes ?
@etiennecoutaud nous offre un REX sur le développement d'opérateur kubernetes, avec les problèmes qu'on peut avoir lorsqu'on dépasse le "hello world".
Son expérience est basé sur l'opérateur utilisé par sa société Artifakt, pour déployer des infras cloud.
Notes
- Artifakt : fait un PaaS multicloud
- Sur le PaaS, ajout d'une couche d'asbtraction pour permettre de deployer sur plusieurs types de cloud provider
- Utilisation de k8s pour utiliser les CRDs afin de permettre avoir un point d'entrée de pilotage
- Plusieurs controleurs dans k8s, sur GCP, qui pilotent les CRDs
- En gros, pour déployer des trucs chez Artifakt, on crée un manifest yaml, et basta
- Kubernetes, c'est ni plus ni moins que des boucles de réconciliations
- status: état observé, spec: état désiré
- Ils utilisent Terraform à la fin, piloté par l'opérateur ;)
Enseignements
- bien définir sa CRD
- utiliser un framework pour construire le controller
- mutating webhook: permet de modifier l'objet avant d'intégrer le cluster (ex istio qui ajoute des sidecar containers)
Conclusion
Sujet que je voulais absolument voir, et je n'ai pas été déçu. Etienne a été clair dans ses explications, des fois un peu trop denses, mais on sort de la conf en ayant vraiment appris des choses, qui seront utiles pour la suite.
15:30 - 16:15 CI/CD, le divorce serait-il prononcé ?
Le couple @nicgiro et @YannSchepens de chez OnePoint nous racontent l'histoire du couple CI/CD, l'un plutôt Dev, l'autre plutôt Ops.
Ils vont essayer de trouver des solutions pour que les 2 mondes s'entendent bien et puissent avoir des longs jours heureux...
Notes
- On débute par la CI (TU, contexte développeur), puis la CD
- D: Delivery, Development, Deployment, pas clair (+ complexe, - automatisé)
- CI: plutôt Dev
- CD: plutôt Ops
- Proposition de pipelines pour que ça marche pour tout le monde
- Définition des objectifs
- Analyse
- Cas particuliers
- Quels feedbacks veut-on (fastfail) ?
- Définir les tâches auto
- Choisir l'outillage. Le meilleur n'est pas forcément le plus adapté au contexte
- Implémentation
- Y aller de manière empirique
- Représenter les processus : Si on ne sait pas représenter, on ne saura pas l'implémenter
- Merge des pratiques Dev & Ops
- DRY:
- Factorisation de code, mais pas trop
- Librairies de jobs
- SOLID
- Essayer de faire des pauses intermédiaires dans le cycle CI/CD, pour pouvoir reprendre en cours de route (pas TOUT redérouler sur un fail)
- KISS
- Ajouter une équipe DevOps : pas forcément le meilleur choix (silo de plus)
3 Choix pour réconcilier
- On sépare Dev & Ops, comme avant, et donc CI & CD séparés, mais au moins on le sait (factuel) et on fait avec
- On laisse ainsi, + équipe DevOps qui sera la pour de la médiation technique
- Intégration de la culture DevOps au sein des équipes
Conclusion
Belle histoire, même si on sens les clichés Dev vs Ops, CI vs CD.
Je note surtout le point de la préparation, bien définir ce qu'on souhaite automatiser, avec les bons outils, pas les meilleurs
16:45 - 17:30 La fin des architectures en couches avec l’approche hexagonale
Fini les confs d'infra, pour terminer les sessions un sujet très orienté dev, présenté par Benjamin Legros: l'archi hexagonale !
Notes
- orienté pour les juniors, pour ne pas se faire avoir avec les concepts appris à l'école, avec l'approche 3-tiers
- gestion des jsonViews, jsonIgnore, etc...
- contraintes sur la couche de présentation, service & persistences... donc le modèle 3-tiers n'est plus valide
- de manière empirique, on arrive à faire du DTO
- "Ports & Adapters", ancêtre de l'archi hexagonale
- le coeur de l'archi: le domaine
- des ports et des adapters
Conclusion
Bon, on va pas se cacher, j'ai pas compris grand chose... chacun sa spécialité, mois c'est clairement pas le dev :P
Fin de la journée
Après tant de sessions, il est temps pour moi de rentrer, encore une journée riche, avec encore de belles conférences et sujets vu et à creuser !
Un peu plus de détails sur mon feedback général dans le prochain article...
